Программирование. Деревья Pascal-Паскаль
Деревья Pascal-Паскаль
Деревья представляют собой иерархическую структуру некой совокупности элементов. Деревья – это одна из наиболее важных нелинейных структур, которые встречаются при работе с компьютерными алгоритмами, их используют при анализе электрических цепей, математических формул, для организации информации в системах управления базами данных и для представления синтаксических структур в компиляторах.
Дерево – это совокупность элементов, называемых узлами (один из которых определен как корень), и отношений («родительских»), образующих иерархическую структуру узлов. Вообще говоря, древовидная структура задает для элементов дерева (узлов) отношение «ветвления», которое во многом напоминает строение обычного дерева.
Формально дерево ( tree ) определяется как конечное множество T одного или более узлов со следующими свойствами:
- Существует один выделенный узел, а именно – корень ( root ) данного дерева;
- Остальные узлы (за исключением корня) распределены среди m ?0 непересекающихся множеств T 1 , T 2 , …. T m , и каждое из этих множеств, в свою очередь, является деревом; деревья T 1 , T 2 , ... T m называются поддеревьями данного корня.
Как видите, это определение является рекурсивным: дерево определено на основе понятия дерево. Рекурсивный характер деревьев можно наблюдать и в природе, например, почки молодых деревьев растут и со временем превращаются в ветви (поддеревья), на которых снова появляются почки, которые также растут и со временем превращаются в ветви (поддеревья) и т.д. Можно привести еще одно формальное определение дерева:
- Один узел является деревом. Этот же узел также является корнем этого дерева.
- Пусть n – это узел, а T 1 , T 2 , ... T m – деревья с корнями n 1 , n 2 , … n m соответственно. Можно построить новое дерево, сделав n родителем узлов n 1 , n 2 , … n m . В этом дереве n будет корнем, а T 1 , T 2 , ... T m – поддеревьями этого корня. Узлы n 1 , n 2 , … n m называются сыновьями узла n .
Из приведенных выше определений следует, что каждый узел дерева является корнем некоторого поддерева данного дерева. Количество поддеревьев узла называется степенью этого узла. Узел с нулевой степенью называется концевым узлом или листом. Неконцевой узел называется узлом ветвления. Каждый узел имеет уровень, который определяется следующим образом: уровень корня дерева равен нулю, а уровень любого другого узла на единицу выше, чем уровень корня ближайшего поддерева, содержащего данный узел.
Рассмотрим эти понятия на примере дерева с семью узлами (см. рисунок). Узлы часто изображаются буквами, они так же, как и элементы списков могут быть элементами любого типа.
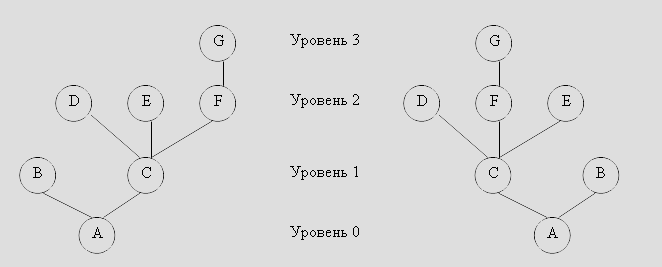
Узел A является корнем, который имеет два поддерева { B } и { C , D , E , F , G }. Корнем дерева{ C , D , E , F , G } является узел C . Уровень узла C равен 1 по отношению ко всему дереву. Он имеет три поддерева { D }, { E }и { F , G }, поэтому степень узла C равна 3. Концевыми узлами (листьями) являются узлы B , D , E , G .
Путем из узла n 1 в узел n k называется последовательность узлов n 1 , n 2 , … n k , где для всех i , 1? i ? k , узел n i является родителем узла n i +1 . Длиной пути называется число, на единицу меньшее числа узлов, составляющего этот путь. Таким образом, путем нулевой длины будет путь из любого узла к самому себе. Например, на рисунке путем длины 2 будет путь от узла A к узлу F или от узла C к узлу G .
Если существует путь из узла a в узел b , то в этом случае узел a называется предком узла b , а узел b – потомком узла a . Отметим, что любой узел одновременно является предком и потомком самого себя. Например, на рисунке предками узла G будут сам узел G и узлы F , C и A . Потомками узла C будут являться сам узел C и узлы D , T , F , G . В дереве только корень не имеет предков, а листья не имеют потомков.
Предок узла, имеющий уровень на единицу меньше уровня самого узла, называется родителем. Потомки узла, уровень которых на единицу больше относительно самого узла, называются сыновьями или детьми. Узлы, являющиеся сыновьями одного родителя, принято называть братьями.
Высотой узла дерева называется длина самого длинного пути от этого узла до какого-либо листа. Глубина узла определяется как длина пути от корня до этого узла.
Лес – это множество (обычно упорядоченное), содержащее несколько непересекающихся деревьев. Узлы дерева при условии исключения корня образуют лес.
Порядок узлов
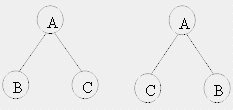
Если в определении дерева имеет значение порядок поддеревьев T 1 , T 2 , ... T m , то дерево является упорядоченным.
Сыновья узла обычно упорядочиваются слева направо. Поэтому деревья, приведенные на рисунке, являются различными.
Если порядок сыновей игнорируется, то такое дерево называется неупорядоченным. Далее будем неявно предполагать, что все рассматриваемые деревья являются упорядоченными, если явно не указано обратное.
Обходы дерева
Существует несколько способов обхода всех узлов дерева. Три наиболее часто используемых способа обхода называются прямой, обратный и симметричный обходы. Все три способа можно рекурсивно определить следующим образом:
- Если дерево T является нулевым деревом, то в список обхода записывается пустая строка;
- Если дерево T состоит из одного узла, то в список обхода записывается этот узел;
- Пусть дерево T имеет корень n и поддеревья T 1 , T 2 , ... T m , как показано на рисунке
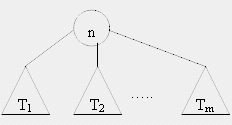
Тогда для различных способов обхода имеем следующее:
- Прямой обход . Сначала посещается корень n , затем в прямом порядке узлы поддерева T 1 , далее все узлы поддерева T 2 и т.д. Последними посещаются в прямом порядке узлы поддерева T m .
- Обратный обход . Сначала посещаются в обратном порядке все узлы поддерева T 1 , затем в обратном порядке узлы поддеревьев T 2 … T m , последним посещается корень n .
- Симметричный обход . Сначала в симметричном порядке посещаются все узлы поддерева T 1 , затем корень n , после чего в симметричном порядке все узлы поддеревьев T 2 … T m .
Рассмотрим пример всех способов обхода дерева, изображенного на рисунке:
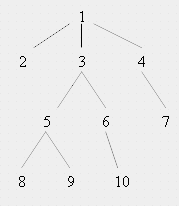
Порядок узлов данного дерева в случае прямого обхода будет следующим:
1 2 3 5 8 9 6 10 4 7.
Обратный обход этого же дерева даст нам следующий порядок узлов: 2 8 9 5 10 6 3 7 4 1.
При симметричном обходе мы получим следующую последовательность узлов:
2 1 8 5 9 3 10 6 7 4.
Помеченные деревья и деревья выражений
Часто бывает полезным сопоставить каждому узлу дерева метку или значение. Дерево, у которого узлам сопоставлены метки, называется помеченным деревом. Метка узла – это значение, которое «хранится» в узле. Полезна следующая аналогия: дерево – список, узел – позиция, метка – элемент.
Рассмотрим пример дерева с метками, представляющее арифметическое выражение ( a + b )*( a + c ), где n 1 , n 2 , …, n 7 – имена узлов, а метки проставлены рядом с соответствующими узлами. Правила соответствия меток деревьев элементам выражений следующие:
- Метка каждого листа соответствует операнду и содержит его значение;
- Метка каждого внутреннего (родительского) узла соответствует оператору.

Часто при обходе деревьев составляется список не имен узлов, а их меток. В случае дерева выражений при прямом обходе получим известную префиксную форму записи выражения, где оператор предшествует обоим операндам. В нашем примере мы получим префиксное выражение вида: *+ ab + ac .
Обратный обход меток дерева дает постфиксное представление выражения (польскую запись). Обратный обход нашего дерева даст нам следующую запись выражения: ab + ac +*.
Следует учесть, что префиксная и постфиксная запись выражения не требует скобок.
При симметричном обходе мы получим обычную инфиксную запись выражения: a + b * a + c . Правда для инфиксной записи выражений характерно заключение в скобки: ( a + b )*( a + c ).
Реализация деревьев
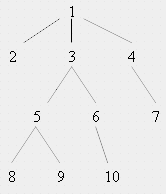
Пусть дерево T имеет узлы 1, 2, …., n . Возможно, самым простым представлением дерева T будет линейный массив A , где каждый элемент A [ i ] содержит номер родительского узла (является курсором на родителя). Поскольку корень дерева не имеет родителя, то его курсор будет равен 0.
Рассмотрим пример.
Для приведенного на рисунке дерева построим линейный массив по следующему правилу: A [ i ]= j , если узел j является родителем узла i , A [ i ]=0, если узел i является корнем. Тогда массив будет выглядеть следующим образом:
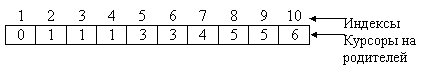
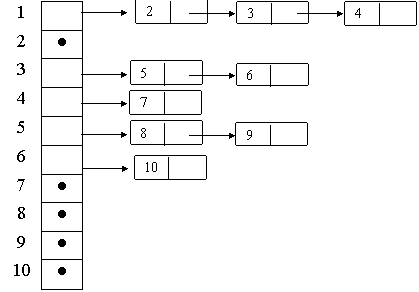
Другой важный и полезный способ представления деревьев состоит в формировании для каждого узла списка его сыновей. Рассмотрим этот способ для приведенного выше примера.
Двоичные деревья
Двоичное или бинарное дерево – это наиболее важный тип деревьев. Каждый узел бинарного дерева имеет не более двух поддеревьев, причем в случае только одного поддерева следует различать левое или правое. Строго говоря, бинарное дерево – это конечное множество узлов, которое является либо пустым, либо состоит из корня и двух непересекающихся бинарных деревьев, которые называются левым и правым поддеревьями данного корня. Тот факт, что каждый сын любого узла определен как левый или как правый сын, существенно отличает двоичное дерево от обычного упорядоченного ориентированного дерева.
Если мы примем соглашение, что на схемах двоичных деревьев левый сын всегда соединяется с родителем линей, направленной влево и вниз от родителя, а правый сын – линией, направленной вправо и вниз, тогда деревья, изображенные на рисунке а) и б) ниже, – это различные деревья, хотя они оба похожи на обычное дерево (рис. в)).
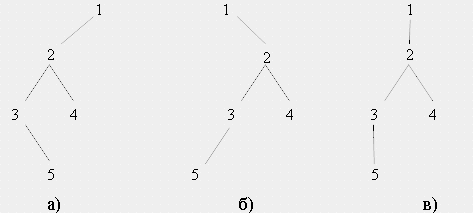
Двоичные деревья нельзя непосредственно сопоставить с обычным деревом.
Обход двоичных деревьев в прямом и обратном порядке в точности соответствует таким же обходам обычных деревьев. При симметричном обходе двоичного дерева с корнем n левым поддеревом T 1 и правым поддеревом T 2 сначала проходится поддерево T 1 , затем корень n и далее поддерево T 2 .
Представление двоичных деревьев
Бинарное дерево можно представить в виде динамической структуры данных, состоящей из узлов, каждый из которых содержит кроме данных не более двух ссылок на правое и левое бинарное дерево. На каждый узел имеется одна ссылка. Начальный узел называется корнем.
По аналогии с элементами списков, узлы дерева удобно представить в виде записей, хранящих информацию и два указателя:
Пример фрагмента программы дереваTree=^s;
S=record
Inf: <тип хранимой информации>;
Left , right : tree ;
End ;
Изобразим схематично пример дерева, организованного в виде динамической структуры данных:
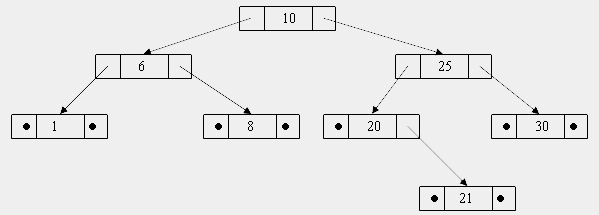
Дерево поиска
Обратите внимание на рисунок, приведенный выше. Данное дерево организовано таким образом, что для каждого узла все ключи (значения узлов) его левого поддерева меньше ключа этого узла, а все ключи его правого поддерева больше. Такой способ построения дерева называется деревом поиска или двоичным упорядоченным деревом.
С помощью дерева поиска можно организовать эффективный способ поиска, который значительно эффективнее поиска по списку.
Поиск в упорядоченном дереве выполняется по следующему рекурсивному алгоритму:
- Если дерево не пусто, то нужно сравнить искомый ключ с ключом в корне дерева:
- если ключи совпадают, поиск завершен;
- если ключ в корне больше искомого, выполнить поиск в левом поддереве;
- если ключ в корне меньше искомого, выполнить поиск в правом поддереве.
- Если дерево пусто, то искомый элемент не найден.
Дерево поиска может быть использовано для построения упорядоченной последовательности ключей узлов. Например, если мы используем симметричный порядок обхода такого дерева, то получим упорядоченную по возрастанию последовательность: 1 6 8 10 20 21 25 30.
Можно организовать «зеркально симметричный» обход, начиная с правого поддерева, тогда получим упорядоченную по убыванию последовательность: 30 25 20 10 8 6 1.
Таким образом, деревья поиска можно применять для сортировки значений.
Операции с двоичными деревьями
Для работы с двоичными деревьями важно уметь выполнять следующие операции:
- Поиск по дереву;
- Обход дерева;
- Включение узла в дерево;
- Удаление узла из дерева.
1. Алгоритм поиска по дереву мы рассмотрели выше. Функция поиска :
Пример функции поискаbegin
p:=root;
while p<>nil do begin
if key=p^.inf then begin{ узел с таким ключом есть }
find:=true;
exit;
end;
parent:=p {запомнить указатель на предка}
if key<p^.inf then
p := p ^. left {спуститься влево}
else p := p ^. right ; {спуститься вправо}
end;
find:=false;
end;
2. Мы рассмотрели несколько способов обхода дерева. Наибольший интерес для двоичного дерева поиска представляет симметричный обход, т.к. он дает нам упорядоченную последовательность ключей. Логично реализовать обход дерева в виде рекурсивной процедуры.
Пример обхода дерева с помощью рекурсииBegin
if p<>nil then
begin
obhod(p^.left);
writeln(p^.inf);
obhod(p^.right);
end;
end;
3. Вставка узла в двоичное дерево поиска не представляет сложности. Для того чтобы вставить узел, необходимо найти его место. Для этого мы сравниваем вставляемый ключ с корнем, если ключ больше, чем ключ корня, уходим в правое поддерево, а иначе – в левое. Тем же образом продвигаемся дальше, пока не дойдем до конечного узла (листа). Сравниваем вставляемый ключ с ключом листа. Если ключ меньше ключа листа, то добавляем листу левого сына, а иначе – правого сына. Например, необходимо вставить в дерево, изображенное на рисунке, узел с ключом 5.
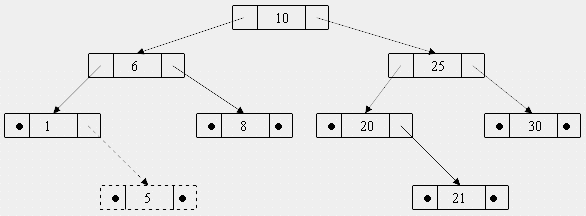
Сравниваем 5 с ключом корня; 5<10, следовательно, уходим в левое поддерево. Сравниваем 5 и 6; 5<6, спускаемся влево. Следующий узел является конечным (листом). Сравниваем 5 и 1; 5>1, следовательно, вставляем правого сына. Получим дерево с новым узлом, которое сохранило все свойства дерева поиска.
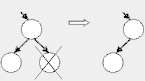
Если узел является конечным (то есть не имеет потомков), то его удаление не вызывает трудностей, достаточно обнулить соответствующий указатель узла-родителя.
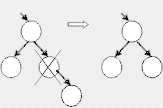
Сложнее всего случай, когда у удаляемого узла есть оба потомка.
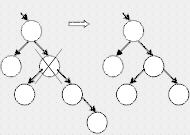
Есть простой особый случай: если у правого потомка удаляемого узла нет левого потомка, удаляемый узел заменяется на своего правого потомка, а его левый потомок подключается вместо отсутствующего левого потомка к замещающему узлу. Рассмотрите этот случай на рисунке, должно стать понятней.
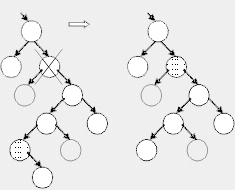
В общем же случае на место удаляемого узла ставится самый левый лист его правого поддерева (или наоборот – самый правый лист его левого поддерева). Это не нарушает свойств дерева поиска.
Корень дерева удаляется по общему правилу за исключением того, что заменяющий его узел не требуется присоединять к узлу-родителю.
Рассмотрим реализацию алгоритма удаления.
Пример программы удаления узла из дереваvar
p : tree ; {удаляемый узел}
parent : tree ; {предок удаляемого узла}
y : tree ; {узел, заменяющий удаляемый}
function spusk(p:tree):tree;
var
y : tree ; {узел, заменяющий удаляемый}
pred:tree; { предок узла “y”}
begin
y:=p^.right;
if y^.left=nil then y^.left:=p^.left {1}
else {2}
begin
repeat
pred:=y; y:=y^.left;
until y^.left=nil;
y^.left:=p^.left; {3}
pred^.left:=y^.right; {4}
y^.right:=p^.right; {5}
end;
spusk:=y;
end;
begin
if not find(root, key, p, parent) then {6}
begin writeln(' такого элемента нет '); exit; end;
if p^.left=nil then y:=p^.right {7}
else
if p^.right=nil then y:=p^.left {8}
else y:=spusk(p); {9}
if p=root then root:=y {10}
else {11}
if key<parent^.inf then
parent^.left:=y
else parent^.right:=y;
dispose(p); {12}
end.
В функцию del передаются указатель root на корень дерева и ключ key удаляемого элемента. С помощью функции find определяются указатели на удаляемый элемент p и его предка parent . Если искомого элемента в дереве нет, то выдается сообщение ( {6}) .
В операторах {7}-{9} определяется указатель на узел y , который должен заменить удаляемый. Если у узла p нет левого поддерева, на его место будет поставлена вершина (возможно пустая) его правого поддерева ({7}).
Иначе, если у узла p нет правого поддерева, на его место будет поставлена вершина его левого поддерева ({8}).
В противном случае, когда оба поддерева существуют, для определения замещающего узла вызывается функция spusk , выполняющая спуск по дереву ({9}).
В этой функции первым делом проверяется особый случай, описанный выше ({1}). Если же этот случай (отсутствие левого потомка у правого потомка удаляемого узла) не выполняется, организуется цикл ({2}), на каждой итерации которого указатель на текущий элемент запоминается в переменной pred , а указатель y смещается вниз и влево до того момента, пока не станет ссылаться на узел, не имеющий левого потомка (он-то нам и нужен).
В операторе {3} к этой пустующей ссылке присоединяется левое поддерево удаляемого узла. Перед тем как присоединять к этому узлу правое поддерево удаляемого узла ({5}), требуется «пристроить» его собственное правое поддерево. Мы присоединяем его к левому поддереву предка узла y , заменяющего удаляемый ({4}), поскольку этот узел перейдет на новое место.
Функция spusk возвращает указатель на узел, заменяющий удаляемый. Если мы удаляем корень дерева, надо обновить указатель на корень ({10}), иначе – присоединить этот указатель к соответствующему поддереву предка удаляемого узла ({11}).
После того как узел удален из дерева, освобождается занимаемая им память ({12}).